AI/ML Frameworks & Libraries Every Developer Must Know in 2026
Read this MyExamCloud Blog article for practical insights on Artificial Intelligence. Explore more blog categories, search related topics in blog search, or return to the MyExamCloud Blog home.
With Best Practices & Practical Guidance
Introduction: The Modern AI Stack
In 2026, the AI/ML ecosystem has matured into a cohesive stack. Python remains the interface, but its libraries—written in high-performance C++, CUDA, and Rust—provide the industrial-grade engine. Whether you're building a simple classifier, a RAG system, or a multi-agent workflow, the right libraries transform weeks of work into minutes.
The landscape now divides into three distinct layers:
- Data & Foundation: NumPy, Pandas, Scikit-learn
- Generative AI & Orchestration: LangChain, LlamaIndex, DSPy
- Deep Learning & Production: PyTorch, TensorFlow, XGBoost, Optuna
To strengthen your career in this evolving ecosystem, consider certifications like AWS Certified AI Practitioner (AIF-C01) and AWS Certified Machine Learning Engineer – Associate (MLA-C01).
Part 1: The Essential Libraries by Category
A. Data Processing & Classical ML (The Foundation)
| Library | Purpose | Best Practice |
|---|---|---|
| NumPy | Numerical computing with N-dimensional arrays. The foundation for all ML math. | Master array operations and broadcasting. Almost every other library builds on it. |
| Pandas | Data wrangling with DataFrames. Handles missing values, transformations, and merging. | Use vectorized operations over loops. For datasets >100GB, consider Dask or Spark. |
| Scikit-learn | Classical ML algorithms (regression, classification, clustering). Consistent fit/predict API. |
Always split data before any preprocessing. Use pipelines to prevent data leakage. |
| XGBoost / LightGBM | Gradient boosting for structured data. Industry standard for tabular problems. | Start with XGBoost for accuracy; switch to LightGBM when speed or memory becomes a constraint. |
| Matplotlib / Seaborn | Visualization for exploration and diagnostics. | Use Seaborn for statistical plots (heatmaps, pair plots); Matplotlib for fine-grained control. |
Career Tip: Strengthen this layer with Databricks Certified Data Engineer Associate.
B. Generative AI & Agent Orchestration (The New Stack)
| Library | Purpose | Best Practice |
|---|---|---|
| LangChain | Orchestration framework for chains, agents, and tool integrations. Vast ecosystem of connectors. | Use LCEL (LangChain Expression Language) for streaming and fallback logic. Pair with official SDKs for latest model features. |
| LlamaIndex | Specialized for RAG (Retrieval-Augmented Generation). Data ingestion, chunking, and query engines. | Ideal for document QA and knowledge bases. Many teams use LlamaIndex for retrieval + LangChain for agents. |
| DSPy | Programmatic prompt optimization. Write with typed signatures; framework optimizes prompts automatically. | Use when prompt tuning becomes manual and time-consuming. Ensures reproducible, testable pipelines. |
| Instructor | Structured output validation. Guarantees LLM responses conform to Pydantic models. | Essential for production applications needing reliable JSON or typed outputs. |
Career Tip: AWS Certified Generative AI Developer Professional (AIP-C01).
C. Deep Learning & Model Development
| Library | Purpose | Best Practice |
|---|---|---|
| PyTorch | Deep learning framework with dynamic computation graphs. Preferred for research and flexibility. | Start with PyTorch for ease of debugging. Increasingly used in production via TorchScript. |
| TensorFlow | Production-focused deep learning with static graphs and extensive deployment tools (TFX, TF Lite). | Better for large-scale production systems and mobile/edge deployment. |
| Hugging Face Transformers | Unified API for thousands of pre-trained models. The standard for open-source NLP and vision. | Use with PEFT for parameter-efficient fine-tuning and Accelerate for distributed training. |
| Optuna | Automated hyperparameter optimization. | Apply after your baseline model works. It systematically improves performance without manual trial-and-error. |
Career Tip: Databricks Certified Machine Learning Professional.
Part 2: Best Practices for 2026
1. Start Simple, Then Specialize
- Beginner path: NumPy → Pandas → Matplotlib → Scikit-learn. This covers 80% of classical ML needs.
- Advanced path: Add LangChain/LlamaIndex for generative AI, or PyTorch for deep learning.
- Avoid: Learning everything at once. Depth in the core stack beats breadth across all tools.
Certification Path: Start with Microsoft Azure AI Fundamentals (AI-900).
2. Think in Workflows, Not Isolated Tools
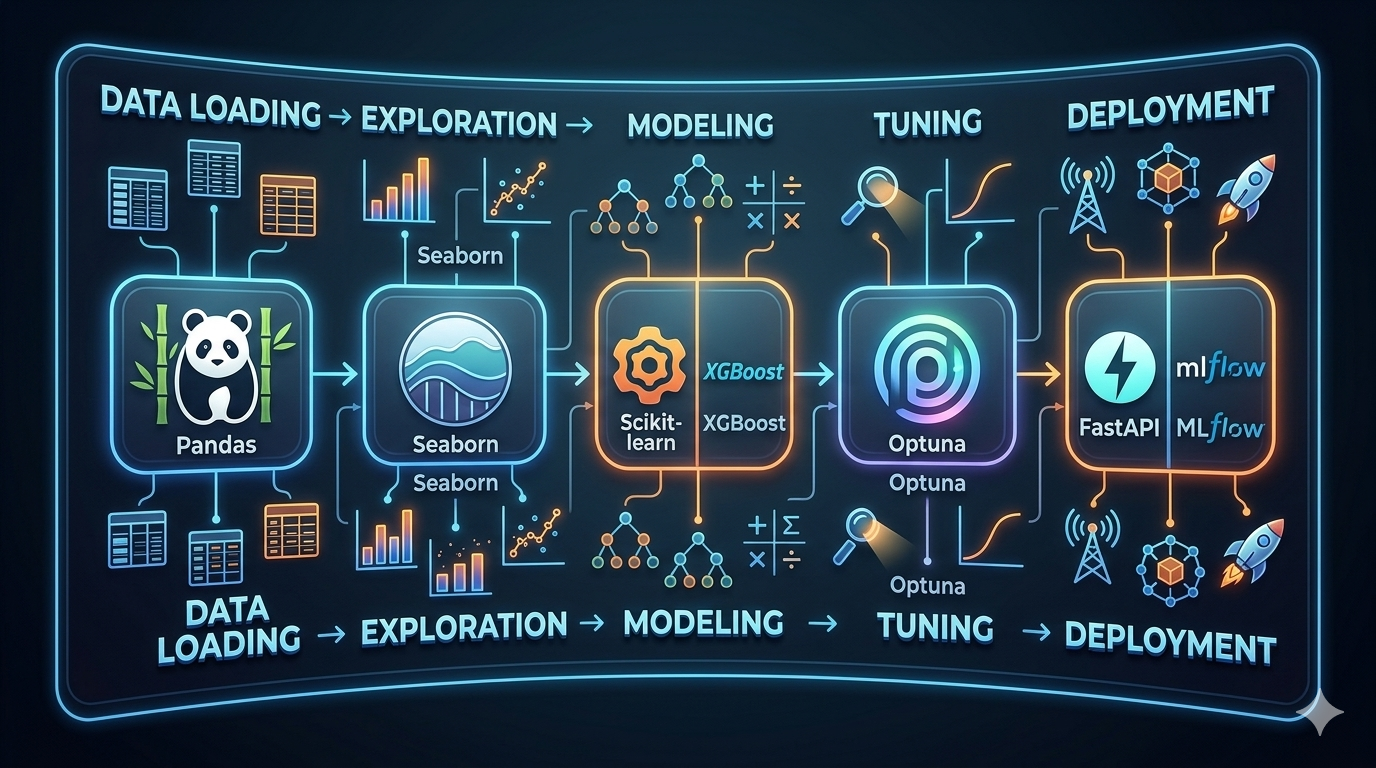
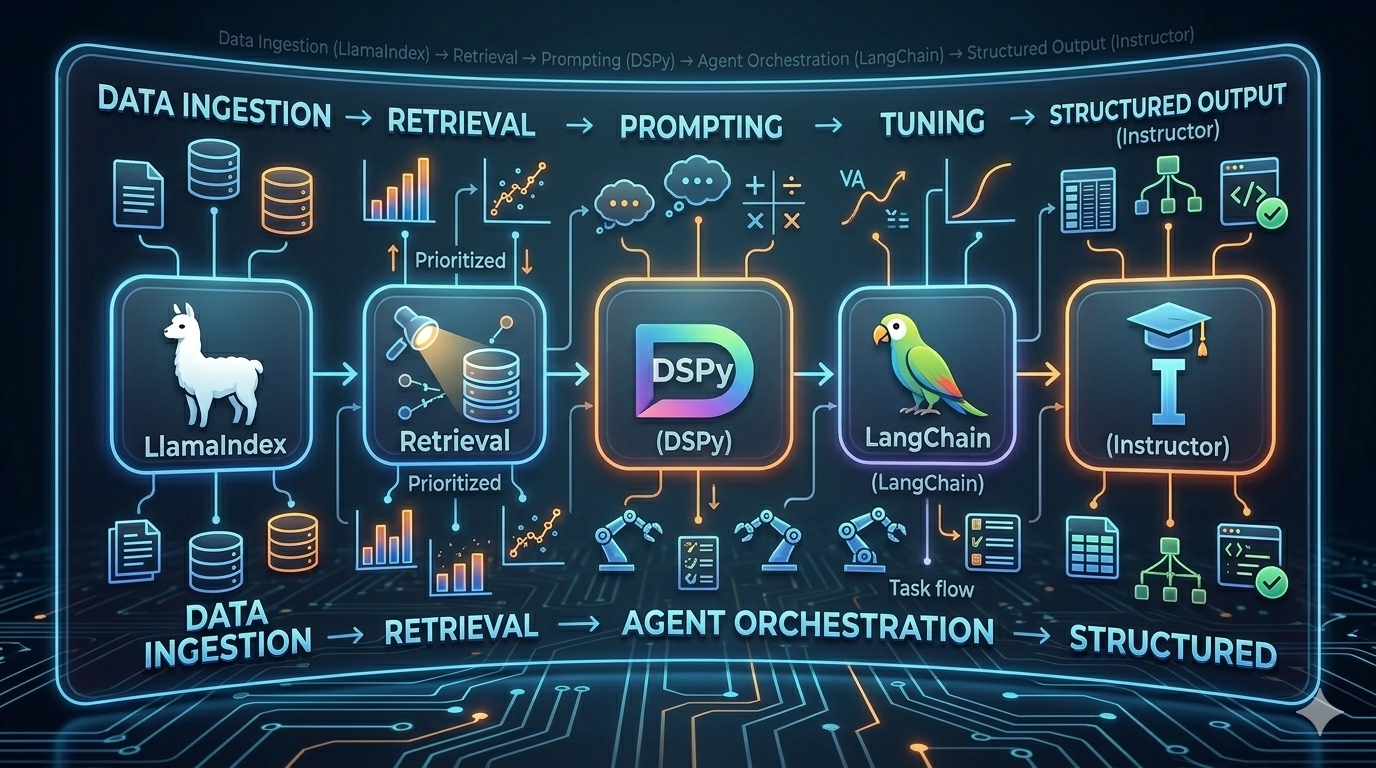
Industry validation: AWS Certified Data Engineer – Associate (DEA-C01).
3. Production-Ready Patterns
- Always validate structured output: Use Instructor or native JSON mode. Never trust raw LLM text in production.
- Implement observability: Use LangSmith, Arize, or similar for tracing agents and chains.
- Handle streaming: Use LCEL in LangChain for token-by-token streaming responses.
- Prevent data leakage: Use Scikit-learn pipelines that apply transformations only on training folds.
Recommended certification: Microsoft Azure AI Engineer Associate (AI-102).
4. Performance Optimization
- For large datasets: LightGBM > XGBoost for speed. Use Dask/Spark when data exceeds memory.
- For deep learning: Start with a small subset to debug. Use mixed precision training (fp16) for speed.
- For LLMs: Cache embeddings. Use async calls for concurrent API requests.
Advanced certification: AWS Certified Machine Learning – Specialty (MLS-C01).
Part 3: How to Choose the Right Stack
| Use Case | Recommended Libraries |
|---|---|
| Classical ML on structured data | Pandas, Scikit-learn, XGBoost, Optuna |
| RAG / Document QA | LlamaIndex, Instructor, Hugging Face Embeddings |
| Agentic Workflows | LangChain / LangGraph, DSPy, official LLM SDKs |
| Computer Vision / NLP Deep Learning | PyTorch / TensorFlow, Hugging Face Transformers |
| Multi-Agent Systems | LangGraph, Google ADK |
| Production Deployment | FastAPI, MLflow, Ray, TensorFlow Serving |
Frequently Asked Questions
Q1: Should I learn TensorFlow or PyTorch in 2026?
A: PyTorch is now more popular in research and is increasingly used in production. TensorFlow remains strong for large-scale industrial systems and edge deployment. Start with PyTorch for flexibility; learn TensorFlow if your target environment requires it.
Q2: Do I need a framework like LangChain, or can I just use the LLM API directly?
A: For simple, single-turn calls, direct API usage is fine. For multi-turn conversations, tool calling, memory, streaming, or RAG, a framework saves significant time. LangChain and LlamaIndex are the industry standards.
Q3: What's the difference between XGBoost and LightGBM?
A: Both are gradient boosting libraries. XGBoost is older and often slightly more accurate. LightGBM trains faster and uses less memory, making it better for large datasets. Try XGBoost first; switch to LightGBM if speed or scale becomes an issue.
Q4: How do I get reliable structured output from LLMs?
A: Use the Instructor library with Pydantic models. It wraps any OpenAI-compatible API and automatically retries with validation feedback if the output is invalid. Most LLM providers also offer native JSON mode.
Q5: Which libraries are essential for a beginner in 2026?
A: Focus on NumPy, Pandas, Matplotlib, and Scikit-learn. These form the core workflow. Once comfortable, add XGBoost for better performance and then explore generative AI libraries based on your project needs.
Q6: What is DSPy and when should I use it?
A: DSPy lets you write AI programs with typed signatures instead of hand-crafted prompts. It automatically optimizes prompts using training data. Use it when you spend more time tuning prompts than building features, or when you need reproducible pipelines.
Q7: How do these libraries connect in a real project?
A: They form a pipeline: data is cleaned in Pandas, visualized in Seaborn, modeled in Scikit-learn or XGBoost, tuned with Optuna, and if needed, integrated into an agent with LangChain using structured output from Instructor. Nothing works in isolation.
Q8: Can I build AI agents without coding?
A: Yes, there are no-code platforms available. However, for custom, production-grade agents, frameworks like LangChain, LangGraph, and Google ADK provide the necessary flexibility and control.
Q9: How important is hyperparameter tuning?
A: Very important. A well-tuned model often outperforms a more complex untuned one. Optuna automates this process and should be part of your workflow after establishing a baseline model.
Q10: What's the best way to practice and learn these libraries?
A: Build complete projects, not isolated snippets. Start with a prediction task on structured data (using Pandas, Scikit-learn), then build a RAG system (LlamaIndex), then an agent (LangChain). Each project should connect multiple libraries in a realistic workflow.
Conclusion: Master the Core, Then Expand
The AI/ML library ecosystem in 2026 is rich but not chaotic. Success comes from:
- Mastering the core 4: NumPy, Pandas, Scikit-learn, and visualization tools
- Understanding workflows rather than isolated functions
- Adding specialized tools (LangChain, PyTorch, XGBoost) based on project needs
- Validating your skills with certifications
Recommended starting point: AWS Certified AI Practitioner (AIF-C01)
| Author | Ganesh P Certified Artificial Intelligence Scientist (CAIS) | |
| Published | 3 months ago | |
| Category: | Artificial Intelligence | |
| HashTags | #Java #Programming #CloudComputing #Software #Architecture #AI #JavaCertification #PythonCertification #genai #machinelearning #ml #placement #career #generativeai #dataanalyst |

